개요
때는 바야흐로 11.4 ML 프로젝트 공지가 올라왔다!
무려 포스터 세션으로 진행되는 프로젝트였기 때문에 열심히 준비해서 멋진 발표를 하고 싶은 욕심이 있었다!

배운 것들을 종합해서 ML 을 활용한 프로젝트를 진행하면 되고,
배운 것에 대한 새로운 제안을 연구(Research) 하고, 현존하는 알고리즘을 흥미로운 문제에 적용시켜본다. (Development)
그리고 마지막으로 여러가지 다른 알고리즘들도 적용해가면서 다양한 성능 측정 지표(performance metrics) 에 대하여 확장 비교 연구를 진행한다. (Evaluation)
주제 선정
가이드라인 교안에 다음과 같은 프로젝트 예시들을 주셨다.
- Handwritten Alphabet/Digit Recognition
- Predictive Stock/House Price Modeling
- Image Classification with CNNs
- Recommendation System
- Face Recognition
- Traffic Flow Prediction
- Chatbot Development or LLM application
- Object Detection in Images
- Human Activity Recognition
근데 꼭 여기서 골라야하는게 아니라, 다른 흥미로운 주제를 선택해도 된다고 하셔서 나는 novelty 점수를 더 받고 싶어서
흥미로워 보이는 새로운 주제를 정했다. <별빛의 주기적인 변화 분석을 통한 👽외계행성찾기> 이다.

어쩌다가 이런 주제를 골랐냐고 한다면,, 사실 지난 10월에 데이터 분석에 ㄷ 자도 모르면서
캐글이라는 데이터 분석 대회 모집 공고를 보고 흥미로워 보인다는 이유로 무모한 도전을 했었다.
아래는 바로 그 문제의 캐글 대회이다.. 😄😃
https://www.kaggle.com/competitions/ariel-data-challenge-2024/overview
NeurIPS - Ariel Data Challenge 2024
Derive exoplanet signals from Ariel's optical instruments
www.kaggle.com
외계 행성의 대기를 분석하기 위한 multimodal supervised learning task 를 수행하고
그 과정에서 관측장비에 의한 jitter noise 왜곡을 제거하는 것이 목적인 대회였다.




그런데 아무래도 경험이 터무니 없이 모자라다보니 어떻게 접근해야할지조차 잘 감이 잡히지 않았고 온갖 수학 공식들만 난무하는 천체관련 논문들을 보며 좌절하고 포기하게 되었다.. ㅎㅎ ㅎ ( 아무래도 현대 천문학에서 가장 어려운 데이터 분석 문제 중 하나라고 하니까..^^ )
비록 그 때 시도했던 주제는 실패했지만, 유사하지만 조금 난이도를 낮춰서
별빛의 주기적인 변화 데이터를 가지고 외계행성의 존재를 예측(Classification)하는 것을 목표로 해보면 어떨까하는 생각이 들었다!
별빛의 주기적인 변화를 가지고 어떻게 외계행성의 존재를 예측할 수 있어 ? 라고 묻는다면,
행성이 별 앞을 지나가면, 별빛의 일부가 가려져서 밝기가 약간 감소한다. 즉, 모행성이 외계행성을 가지고 있으면 그 외계행성이 모행성 중심으로 공전하기 때문에 관측 하는 입장에서는 주기적으로 감지 가능한 부분을 막아 빛의 밝기가 감소하는 것을 관측할 수 있다.
이러한 별의 주기적인 밝기 변화의 패턴을 감지하여 최종적으로 외계행성이 존재하는지 여부를 관측하고자 하는 것이 우리의 목적이다.
그렇게 나랑 내 팀원은 "외계 행성을 찾기 위한 우주 로의 여행" 을 떠났다! 레츠 기릿 😎
외계 행성 찾기
데이터셋
NASA 케플러 우주망원경에서 가져온다. 이 데이터셋에서 5,050 개는 외계행성이 없고 오직 37개만 외계 행성이 존재한다.

빛의 주기적인 변화를 관찰해서 주기성을 찾으려면 충분한 데이터 포인트가 필요하다.
태양계 안에 있는 행성의 공전은 88년 ~ 165년까지 다르다.
그래프 시각화
시계열 데이터셋에서 통찰을 얻기 위해서 그래프를 그려보자. 가로축은 관측 횟수이고 세로축이 광속(Light Flux)이다.
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set()
X = df.iloc[:,1:]
y = df.iloc[:,0] - 1
def light_plot(index):
y_vals = X.iloc[index]
x_vals = np.arange(len(y_vals))
plt.figure(figsize=(15,8))
plt.xlabel('Number of Observations')
plt.ylabel('Light Flux')
plt.title('Light Plot ' + str(index), size=15)
plt.plot(x_vals, y_vals)
plt.show()
분명 데이터에 주기적으로 나타나는 별의 밝기 증감이 있다.
어떤 행성은 주기적으로 빛이 감소한다. 외계 행성이 있을 가능성이 높다.

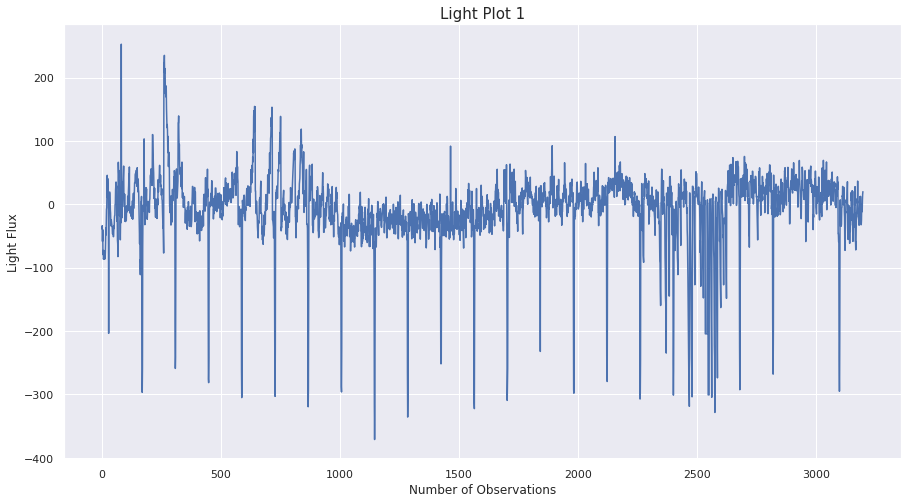
반면, 어떤 행성은 매우 잠잠한 것을 볼 수 있다.

하지만 그래프만으로는 외계행성 존재 여부를 판별하기에는 확실치 않다.
이 데이터셋은 시계열 데이터이지만, 다음 번의 광속을 예측하는 회귀 문제가 아닌 외계 행성을 가진 별을 분류(Classificatoin)하는 문제이다.
모델 선정
문제 해결을 위하여 어떤 모델을 사용해야할까? 연관성이 높아보이는 모델군들을 조사해보았다.
1. 전통적인 시계열 분석 모델
ARIMA (AutoRegressive Integrated Moving Average)
- 데이터가 비교적 단순하고, 노이즈가 적은 경우 적합
- 별빛의 밝기 데이터에서 주기적인 변화를 감지하고 이상값(Transit)을 탐지
- 한계: 복잡한 비선형 패턴이나 다중 주기를 다루는 데는 부족.
2. 머신러닝 기반 모델
1) 랜덤 포레스트 (Random Forest)
- 별빛 데이터의 특징(밝기 변화의 크기, 주기, 노이즈 등)을 추출한 뒤 이를 분류 문제로 접근
- 데이터가 비교적 작거나 설명 가능한 모델이 필요할 때 적합
- 단점: 시계열 데이터 자체를 처리하기에는 적합하지 않음(특징 추출 과정 필요)
2) Gradient Boosting 계열 (e.g., XGBoost, LightGBM)
- 랜덤 포레스트와 유사하지만, 데이터에서 더 복잡한 상호작용을 학습
- 특징 추출 후 밝기 패턴이 행성에 의한 것인지 아닌지 분류하는 데 적합
3. 딥러닝 기반 모델
1) 순환 신경망 (RNN, LSTM, GRU)
- 시계열 데이터의 패턴을 학습하는 데 특화된 모델
- LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)는 긴 시계열 데이터를 학습할 수 있어 주기적이고 복잡한 밝기 변화를 감지하는 데 유용
- 장점: 데이터의 시간적 종속성을 효과적으로 학습
- 단점: 학습에 많은 데이터와 시간이 필요
2) 1D 합성곱 신경망 (1D CNN)
- 시계열 데이터에서 지역적 패턴(특정 밝기 변화 패턴)을 학습
- 별빛의 밝기 변화에서 행성의 Transit 신호를 감지하는 데 자주 사용
3) 하이브리드 모델 (CNN + LSTM)
- CNN으로 지역적 패턴(Transit 신호)을 학습하고, LSTM으로 전체 시계열 패턴(주기적 변화)을 학습
사실 XGBoost 가 대부분의 캐글 대회에서 우승을 차지할만큼 성능이 좋은 모델로 알려져있다.
그래서 XGBClassifier 를 사용해 먼저 분류 작업을 수행해볼 것이다.
데이터 준비
초기 XGBClassifier
# XGBRegressor를 임포트합니다.
from xgboost import XGBClassifier
# accuracy_score를 임포트합니다.
from sklearn.metrics import accuracy_score
# train_test_split를 임포트합니다.
from sklearn.model_selection import train_test_split
# 데이터를 훈련 세트와 테스트 세트로 나눕니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2)
# XGBClassifier를 초기화합니다.
model = XGBClassifier(booster='gbtree')
# 훈련 세트로 모델을 훈련합니다.
model.fit(X_train, y_train)
# 테스트 세트에 대한 예측을 만듭니다.
y_pred = model.predict(X_test)
score = accuracy_score(y_pred, y_test)
print('점수: ' + str(score))
점수: 0.89
이 데이터셋에서 외계 행성을 가진 별은 37 / ( 5,050 + 37 ) % 뿐이다. 즉 10% 도 채 되지 않는다.
따라서 무조건 외계 행성이 없다고 예측하는 모델이 있다면 이 모델이 더 낫다고 말하기 어려울 것이다.
불균형한 데이터셋에서는 정확도로는 충분하지 않다는 깨달음을 얻는다.
여러가지 평가지표
오차행렬 분석
분류 모델의 성능을 평가하기 위해 사용되는 표로, 실제 값과 모델의 예측 값 간의 비교를 기반으로 만들어진다.
어떤 예측이 정확하고 어떤 예측이 틀렸는지에 대한 정보를 제공하므로 불균형한 데이터셋을 분석하는 데 이상적이다.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred)array([[86, 2],
[ 9, 3]])
우리는 주어진 데이터셋에 대하여 외계 행성을 가진 별을 모두 찾는 것이 목표이다. 가능한 많은 외계 행성을 찾는 것이 좋으므로 재현율을 중요하게 보자. 재현율은 외계 행성을 가진 행성 중에서 실제로 몇개의 행성을 찾았는지를 알려준다.

- 정밀도 : 3 / (3 + 2) = 60% 확률로 외계행성이라고 예측한 것이 실제로 정답이다.
- 재현율 (Recall) : 3 / ( 3 + 9) = 25% 확률로 양성 샘플을 찾는다.
- 정확도 : 89 / 100 = 89% 확률로 추측한 답이 정답이다.
classification_report
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
precision recall f1-score support
0 0.91 0.98 0.94 88
1 0.60 0.25 0.35 12
accuracy 0.89 100
macro avg 0.75 0.61 0.65 100
weighted avg 0.87 0.89 0.87 100
[0] 은 음성 샘플에 대한 precison, recall 이고 [1]은 양성 샘플에 대한 precison, recall 이다.
F1 점수는 정밀도와 재현율의 조화 평균이다. 정밀도와 재현율의 분모가 다르므로 이를 동일하게 만들기 위해서 사용한다.
정밀도와 재현율 모두 중요할 때는 F1 점수를 사용하면 좋다. 0 ~ 1 사이 값이며 1이 가장 좋은 값이다.
ROC 곡선
불균형 데이터 리샘플링
앞선 classification_report 에서 굉장히 낮은 재현율 점수를 기록하는 것을 보았다.
그 이유는 애초에 양성 샘플 개수가 음성 샘플보다 턱없이 모자랐기 때문이다.
- 클래스 불균형 문제란, 목표 변수(Target)의 클래스 비율이 크게 차이 나는 경우를 말한다. 예를 들어, 데이터에서 Positive 클래스(1)가 10%, Negative 클래스(0)가 90%라면 모델은 Negative 클래스에 치우친 예측을 하게 될 가능성이 높다.
- scale_pos_weight는 이러한 상황을 완화하기 위해 Positive 클래스에 가중치를 부여하여, Positive 클래스에 대한 학습의 중요성을 높이는 역할
예를 들어서 양성 샘플이 두개 뿐이라면, 그 중 하나만 제대로 못맞춰도 50% 재현율을 기록한다.
따라서 낮은 재현율 점수를 만드는데 데이터 불균형 문제를 고치기 위해 불균형 데이터를 리샘플링할 것이다.
다수 클래스의 샘플을 줄이기 위해 데이터를 언더샘플링 하거나 소수 클래스 샘플을 늘리기 위해 오버샘플링할 수 있다.
언더샘플링
데이터에서 다수 클래스(majority class)의 샘플을 줄여서 소수 클래스(minority class)와 균형을 맞추는 방법.
클래스 분포를 균형 있게 만들어, 모델이 다수 클래스에 치우치지 않도록 학습을 유도한다.
데이터 크기를 줄이기 때문에 처리 속도가 빨라지며, 간단하고 구현이 용이하다.
그러나, 다수 클래스의 정보를 손실할 가능성이 있다.
언더샘플링 기법
- 랜덤 언더샘플링(Random Under-sampling): 다수 클래스 데이터를 무작위로 제거.
- 클러스터링 기반 샘플링: 클러스터링을 통해 데이터를 그룹화하고, 각 그룹에서 대표 샘플을 선택.
xgb_clf 함수는 언더샘플링 결과가 어떻게 변하는지 알 수 있도록 재현율 점수를 반환한다.
def xgb_clf(model, nrows):
df = pd.read_csv('exoplanets.csv', nrows=nrows)
# 데이터를 X와 y로 나눕니다.
X = df.iloc[:,1:]
y = df.iloc[:,0] - 1
# 데이터를 훈련 세트와 테스트 세트로 나눕니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2)
# 훈련 세트에서 모델을 훈련합니다.
model.fit(X_train, y_train)
# 테스트 세트에 대한 예측을 만듭니다.
y_pred = model.predict(X_test)
score = recall_score(y_test, y_pred)
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
return score
nrows 를 바꾸어 가면서 재현율 점수가 어떻게 변하는지 살펴보자.
xgb_clf(XGBClassifier(), nrows=800)
[[189 1]
[ 9 1]]
precision recall f1-score support
0 0.95 0.99 0.97 190
1 0.50 0.10 0.17 10
accuracy 0.95 200
macro avg 0.73 0.55 0.57 200
weighted avg 0.93 0.95 0.93 200
0.1
외계 행성이 없는 별의 재현율은 거의 완벽하지만, 외계 행성이 있는 별의 재현율은 10%에 불과하다.
만일 외계 행성을 지닌 별과 없는 별의 개수를 37개로 동일하게 맞추면 균형이 맞는다.
xgb_clf(XGBClassifier(), nrows=74)
[[6 2]
[5 6]]
precision recall f1-score support
0 0.55 0.75 0.63 8
1 0.75 0.55 0.63 11
accuracy 0.63 19
macro avg 0.65 0.65 0.63 19
weighted avg 0.66 0.63 0.63 19
0.5454545454545454오버샘플링
데이터에서 소수 클래스(minority class)의 샘플을 늘려서 다수 클래스와 균형을 맞추는 방법이다.
소수 클래스 데이터를 늘려서 모델이 소수 클래스에 대해 더 잘 학습하도록 유도한다.
기존 데이터를 보존하면서 모델이 소수 클래스에 대한 학습을 강화할 수 있으나, 과적합(overfitting)의 위험이 있다.
nrow = 400 일 때, 음성:양성 비율은 약 10대 1이다. 따라서 균형을 맞추기 위해 양성 클래스 샘플을 10배 늘린다.
이를 위한 전략은 다음과 같다.
- 양성 클래스 샘플을 아홉번 복사한 새로운 df 를 만든다.
- 새로운 df 와 원본 df 를 합쳐서 1:1 비율을 만든다.
여기서 주의할 점이 있는데, 데이터를 훈련 세트와 테스트 세트로 나누기 전에 리샘플링하면 재현율 점수가 부풀려진다.
왜일까? 나누기전에 오버 샘플링하고 이를 훈련/테스트 세트로 나누면 복사본이 두 세트 모두에 들어갈 가능성이 높기 때문이다.
따라서 이미 학습한 동일한 샘플에 대해 예측 결과를 출력하므로 제대로된 Test 를 수행하고 있다고 보기 어렵게 된다.
적절한 방법은 훈련 세트와 테스트 세트를 먼저 나누고 그다음 리샘플링을 수행하는 것이다.
1. x_train 과 y_train 을 합친다.
두 데이터프레임의 인덱스 값이 같은 행끼리 병합된다.
df_train = pd.merge(y_train, X_train, left_index=True, right_index=True)
2. np.repeat() 함수를 통하여 새로운 데이터 프레임 newdf 를 만든다.
- 양성 샘플을 넘파이 배열로 변환한다.
- 복사 횟수 9를 지정한다.
- 행을 기준으로 복사하기 위해 axis=1 을 지정한다.
- 열 이름을 복사하고 데이터 프레임을 연결한다.
newdf = pd.DataFrame(np.repeat(df_train[df_train['LABEL']==1].values,
9,axis=0))
newdf.columns = df_train.columns
df_train_resample = pd.concat([df_train, newdf])
df_train_resample['LABEL'].value_counts()0.0 275
1.0 250
Name: LABEL, dtype: int64
양성 샘플과 음성 샘플 사이 균형이 맞도록 데이터가 증강된 것을 확인할 수 있다!
3. 리샘플링 된 데이터 프레임을 X와 y로 나눈다.
X_train_resample = df_train_resample.iloc[:,1:]
y_train_resample = df_train_resample.iloc[:,0]
4. 모델 훈련
# XGBClassifier를 초기화합니다.
model = XGBClassifier()
# 훈련 세트로 모델을 훈련합니다.
model.fit(X_train_resample, y_train_resample)
# 테스트 세트에 대해 예측을 만듭니다.
y_pred = model.predict(X_test)
score = recall_score(y_test, y_pred)
5. 오차 행렬과 분류 리포트 출력
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
print(score)[[86 2]
[ 8 4]]
precision recall f1-score support
0 0.91 0.98 0.95 88
1 0.67 0.33 0.44 12
accuracy 0.90 100
macro avg 0.79 0.66 0.69 100
weighted avg 0.89 0.90 0.88 100
0.3333333333333333
시작할 때 만든 테스트 세트를 사용하여 오버샘플링으로 33.3% 재현율을 달성하였다.
여전히 낮지만 이전에 얻은 17%보다는 두배 높은 점수이다.
리샘플링으로는 성능이 크게 올라가지 않았으므로 XGBoost의 매개변수를 튜닝해볼 차례이다.
XGBClassifier 튜닝
가능한 최상의 재현율 점수를 얻도록 튜닝할 것이다.
1. scale_pos_weight 매개변수를 사용해 가중치를 조정하고
2. 그리드 서치로 최상의 매개변수 조합을 찾는다.
가중치 조정하기
scale_pos_weight의 값은 다수 클래스와 소수 클래스 간의 비율을 기반으로 설정된다.

# 데이터를 X와 y로 나눕니다.
X = df.iloc[:,1:]
y = df.iloc[:,0]
# 데이터를 훈련 세트와 테스트 세트로 나눕니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2)
model = XGBClassifier(scale_pos_weight=10)
model.fit(X_train, y_train)
# 테스트 세트에 대한 예측을 만듭니다.
y_pred = model.predict(X_test)
score = recall_score(y_test, y_pred)
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
print(score)
재현율: [0.10526316 0.27777778]
재현율 평균: 0.1915204678362573
이 결과는 리샘플링으로 얻은 것과 동일하다.
직접 구현한 오버 샘플링 방법은 scale_pos_weight 매개변수를 사용하여 만든 XGBClassifier와 동일한 예측을 만든다.
하이퍼파라미터 튜닝 ( grid_search )
하이퍼파라미터 튜닝을 할 때에는 랜덤 or 그리드 서치를 수행하는 것이 표준이다. 두 클래스 모두 두 개 이상의 폴드로 교차 검증을 수행하며, 대규모 데이터셋에서 여러 폴드를 테스트 하는 것이 오래 걸리므로 두개의 폴드만 사용한다. 일관된 결과를 위하여 StratifiedFold 를 사용하는 것이 권장된다.
📌 StratifiedFold 란?
StratifiedKFold는 scikit-learn 라이브러리에서 제공하는 교차 검증 방법 중 하나로, 클래스 비율을 균형 있게 유지하며 데이터를 분할하는 데 사용된다. 각 폴드(Fold) 내에서 원래 데이터의 클래스 비율을 유지하도록 데이터를 나눈다. 예를 들어, 전체 데이터에서 Positive:Negative 비율이 1:9라면, 각 폴드에서도 이 비율이 유지된다.
기준 모델
k-fold 교차 검증으로 기준 모델을 만든다.
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV,StratifiedKFold, cross_val_score
kfold = StratifiedKFold(n_splits=2, shuffle=True, random_state=2)
model = XGBClassifier(scale_pos_weight=10)
# 교차 검증 점수를 계산합니다.
scores = cross_val_score(model, X, y, cv=kfold, scoring='recall')
# 재현율을 출력합니다.
print('재현율: ', scores)
# 재현율의 평균을 출력합니다.
print('재현율 평균: ', scores.mean())재현율: [0.10526316 0.27777778]
재현율 평균: 0.1915204678362573
교차 검증을 하니까 성능이 더욱 나빠졌다..ㅎㅎ 아무래도 양성 샘플이 적을 때에는 어떤 샘플이 훈련 세트와 테스트 세트에 포함되는지가 차이를 만들 것이다.
grid_search
def grid_search(params, random=False, X=X, y=y,
model=XGBClassifier(scale_pos_weight=10, random_state=2)):
xgb = model
if random:
grid = RandomizedSearchCV(xgb, params, cv=kfold, n_jobs=-1,
random_state=2, scoring='recall')
else:
# 그리드 서치 객체를 초기화합니다.
grid = GridSearchCV(xgb, params, cv=kfold, n_jobs=-1, scoring='recall')
# X_train와 y_train으로 훈련합니다.
grid.fit(X, y)
# 최상의 매개변수를 추출합니다.
best_params = grid.best_params_
# 최상의 매개변수를 출력합니다.
print("최상의 매개변수:", best_params)
# 최상의 점수를 추출합니다.
best_score = grid.best_score_
# 최상의 점수를 출력합니다.
print("최상의 점수: {:.5f}".format(best_score))
그리고 노가다를 돌린다..

최상의 매개변수: {'gamma': 0.025, 'learning_rate': 0.001, 'max_depth': 2}
최상의 점수: 0.53509
최상의 매개변수: {'subsample': 0.3, 'colsample_bytree': 0.7, 'colsample_bynode': 0.7, 'colsample_bylevel': 1}
최상의 점수: 0.37865균형 잡힌 서브셋
74개 샘플로 이루어진 균형잡힌 서브셋은 최소한 양의 데이터이기에 테스트하기도 빠르다.
이 서브셋에 그리드 서치를 수행하여 최상의 매개변수를 찾는다.
X_short = X.iloc[:74, :]
y_short = y.iloc[:74]grid_search(params={'max_depth':[1, 2, 3],
'colsample_bynode':[0.5, 0.75, 1]},
X=X_short, y=y_short,
model=XGBClassifier(random_state=2))최상의 매개변수: {'colsample_bynode': 0.5, 'max_depth': 1}
최상의 점수: 0.65205전체 데이터로 튜닝하기
전체 데이터로 grid_search() 를 호출하면 굉장히 오래 걸린다.
음성 클래스 개수 / 양성 클래스 로 가중치를 계산한다. 그리고 해당 가중치를 scale_pos_weight 에 적용하여 모델을 만든다.
weight = int(5050/37)
model = XGBClassifier(scale_pos_weight=weight)
# 교차 검증 점수를 계산합니다.
scores = cross_val_score(model, X_all, y_all, cv=kfold, scoring='recall')
# 재현율을 출력합니다.
print('재현율:', scores)
# 재현율의 평균을 출력합니다.
print('재현율 평균:', scores.mean())
점수가 아주 좋지 않다.
재현율: [0.10526316 0. ]
재현율 평균: 0.05263157894736842
지금까지 제일 좋았던 매개변수를 기반으로 하이퍼파라미터 튜닝을 해본다.
이 점수는 앞서 언더샘플링한 데이터셋의 결과만큼은 아니지만 더 나아졌다.

전체 데이터를 사용한 점수가 낮고 시간이 오래걸렸으니 "외계 행성 데이터셋의 작은 서브셋에서 ML 모델이 더 잘 동작할까요?" 라는 질문이 생긴다.
결과 통합
지금까지 다음과 같은 서브셋을 시도해보았다.
- 5050개 샘플 -> 약 54% 재현율
- 400개 샘플 -> 약 54% 재현율
- 74개 샘플 -> 약 68% 재현율
가장 좋은 점수를 낸 매개변수는 learning_rate = 0.001, max_depth=2, colsample_bynode=0.5 이다.
외계 행성을 가진 37개의 별을 모두 포함해 모델을 훈련한다. 이는 테스트 세트에 모델 훈련에 사용한 샘플이 포함된다는 의미이다.
일반적으로 이는 좋은 생각이 아니지만, 이 예제에서는 양성 클래스가 매우 적기 때문에 이전에 본 적 없는 양성 샘플로 이루어진 더 작은 서브셋을 테스트 하는 방법을 알아보는데 도움이 될 수 있다.
def final_model(X, y, model):
model.fit(X, y)
y_pred = model.predict(X_all)
score = recall_score(y_all, y_pred)
print(score)
print(confusion_matrix(y_all, y_pred))
print(classification_report(y_all, y_pred))
74개 샘플
final_model(X_short, y_short,
XGBClassifier(max_depth=2, colsample_by_node=0.5,
random_state=2))
1.0
[[3588 1462]
[ 0 37]]
precision recall f1-score support
0 1.00 0.71 0.83 5050
1 0.02 1.00 0.05 37
accuracy 0.71 5087
macro avg 0.51 0.86 0.44 5087
weighted avg 0.99 0.71 0.83 5087
외계 행성을 가진 37개의 별을 모두 완벽하게 분류했다. 하지만 외계 행성이 없는 0.29 의 샘플(1,462) 를 잘못 분류했다.
게다가 정밀도는 2%이며, F1 점수는 5%이다. 재현율만 튜닝할 때에는 지나치게 낮은 정밀도와 F1 점수가 위험 요인이다.
400개 샘플
final_model(X, y,
XGBClassifier(max_depth=2, colsample_bynode=0.5,
scale_pos_weight=10, random_state=2))
1.0
[[4897 153]
[ 0 37]]
precision recall f1-score support
0 1.00 0.97 0.98 5050
1 0.19 1.00 0.33 37
accuracy 0.97 5087
macro avg 0.60 0.98 0.66 5087
weighted avg 0.99 0.97 0.98 5087
여기도 재현율 100%를 달성하지만,
외계 행성이 없는 경우의 재현율이 0.19로 149개의 별을 잘못 분류한다.
이 경우 외계 행성이 있는 별 37개를 찾기 위해서 190개의 별을 분석해야한다.
5,050 샘플
final_model(X_all, y_all,
XGBClassifier(max_depth=2, colsample_bynode=0.5,
scale_pos_weight=weight, random_state=2))1.0
[[5050 0]
[ 0 37]]
precision recall f1-score support
0 1.00 1.00 1.00 5050
1 1.00 1.00 1.00 37
accuracy 1.00 5087
macro avg 1.00 1.00 1.00 5087
weighted avg 1.00 1.00 1.00 5087
모든 예측, 재현율, 정밀도가 100%로 완벽하다.
하지만 유념해야할 점은, 원래는 강력한 모델을 만들기 위해서 모델이 본 적 없는 테스트 세트를 사용하는 것이 필수적이지만 여기에서는 훈련 데이터에서 이 점수를 얻었다. 따라서 모델이 훈련 데이터를 완벽하게 학습했더라도 새로운 데이터에 잘 일반화될 가능성이 낮다.
데이터에 있는 미묘한 패턴을 잡아내려면 더 많은 트리와 더 많은 튜닝이 필요할 수 있다.
결과 분석
정밀도를 사용한 사용자는 일반적으로 50~70%를 달성했고, 재현율을 사용한 사용자는 60~100%를 달성했다.
불균형한 데이터의 한계를 알고 있다면 모델의 성능은 최대 70% 재현율이며, 외계 행성을 가진 37개의 별로는 생명체나 다른 행성을 찾기 위해 강력한 머신러닝 모델을 만들기에는 충분하지 않다.
'CS > 인공지능' 카테고리의 다른 글
| k-평균 알고리즘 (k-means clustering) 구현 (0) | 2024.10.18 |
|---|---|
| SVM 을 활용한 스팸 분류기 ( Spam Classification via SVM ) (1) | 2024.10.17 |
| 나이브 베이즈를 사용한 스팸 메일 분류기 (Spam Classification via Naïve Bayes) (3) | 2024.10.17 |
| [Tensorflow keras] image generation using Stable Diffusion (0) | 2024.06.24 |
| Simple Diffusion Image generate Model (0) | 2024.06.21 |



